Releases
Release 2024.04.00
Notable Changes
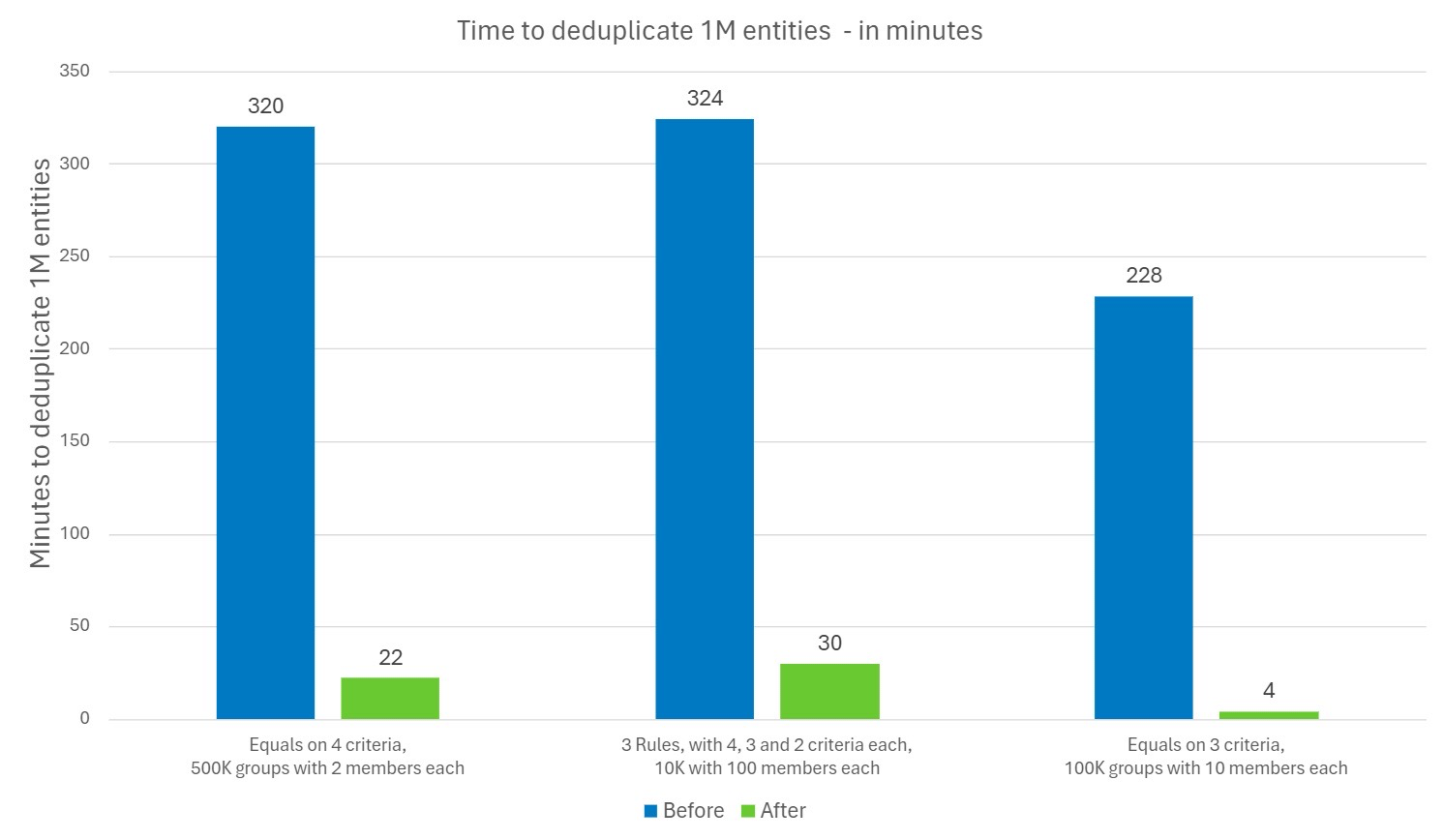
Deduplication Project Perfomance Improvements
A completely new execution planner and rule executer have been introduced to optimize different kinds of rule configurations. The execution planner dynamically re-orders rule execution according to the most optimal order for the given dataset. As a result, the generation of deduplication projects has been greatly improved in many common scenarios.
The following rule conditions have been improved:
- Equals comparison with no normalizations
- Equals comparison with normalizations
- Other comparison types than Equals with fewer than 10,000 unique values
Note: If the number of unique values for fuzzy comparison exceeds 10K, the rule planner will fall back to the old execution engine.
Rules with multiple conditions: Evaluation of multiple Equals conditions with no normalization options set has greatly improved.
Benchmark with a dataset of 1 million entities:
Data Source Performance
A thorough review of the data flow has been conducted to enhance performance and resilience when pushing data to CluedIn. The system now primarily operates based on the number of data source processing pods it possesses. With the new changes, an instance running with only one data source processing pod can still receive millions of records without exceeding the limit set by the Kubernetes cluster. The pod will only take what it can, when it can. As demonstrated in the benchmark test results, the performance with only one data source processing pod is already quite significant, capable of ingesting a million records in about 10 minutes. To further improve performance, you can scale the data source processing to two or three replicas. There is no need to increase the number of submitters, as two pods are already sufficient to process millions of records.
Benchmark Scenario:
- Setup an Ingestion Endpoint
- Send 10 records of 21 properties
- Map the Data Set
- Enable Auto-submission
- Send the payload
The scenario was executed for each payload size.
| # | Test name | Duration | Submission Duration |
|---|---|---|---|
| 1. | Simple data - 10 | 55 ms | 256 ms |
| 2. | Simple data - 100 | 109 ms | 538 ms |
| 3. | Simple data - 1000 | 533 ms | 2 719 ms |
| 4. | Simple data - 10000 | 521 ms | 5 155 ms |
| 5. | Simple data - 1000000 | 373 403ms | 652 504 ms |
Duration: The amount of time it took for the system to receive all the required payloads, by batches of 1000 records. Submission Duration: The amount of time between the start of the test and the time when all records were sent to processing.
NOTE: For large dataset, we advise you to use a 10K payload size per request.
The benchmark was executed against an Essential CluedIn instance with:
- 1 Data Source Pod
- 1 Data Source Processing Pod
- 2 Submitter Pod
- 2 Processing Box
Vocabulary Key Remapping
Throughout the system, we have overhauled and unified the way you interact with mapped vocabulary keys. You will see more information when you have used a mapped vocabulary key in the system and you will have easy access to link back to the vocabulary keys that are impacted. This provides you with a better understanding of where data ends up in your system and which keys you might want to prioritize.
Alongside this, we have improved the remapping process, and more checks are performed in the system to ensure that nothing will be broken when a vocabulary key is remapped. We display the impact, such as how many streams, saved searches, glossaries and clean projects will be affected by remapping a vocabulary key. If there are any compatibility issues, such as incompatible data types, we automatically disable any affected areas and inform the user of the action, allowing you to go and select the correct settings and re-enable the affected areas.
CluedIn Clean
Clean now has a more cohesive flow with CluedIn. Instead of being taken to a separate tab to work on your clean projects everything is now inline and gives a much more streamlined experience when working with clean projects.
Allow local user passwords for SSO users to be reset
Users that have and SSO account can now change their local password. It is a small but important change that will help in areas such as token use or whilst using the excel plugin.
Release Notes
CluedIn
Features
- Improved vocabulary and vocabulary key lookup performance
- Allow the
EqualsOperatorto be used with boolean properties and vocabulary keys in the query builder - Improved deduplication generation performance
- The number of matches in a deduplication group accounts for removed entities from within the group
- Vocabulary key mapping reworked throughout the system
- Hierarchy projects have a provider definition associated with them
Fixes
- GraphQL processOutgoingStreams action throws an exception
- Search using lookup key values are not returning the correct results
- Merging entities can cause data inconsistency under certain conditions
- In some scenarios the billable records counts would include shadow entities
- Removing an edge that points to a shadow entity in topology could result in the removed edge being resurrected when the shadow entity is reprocessed
- Application crashes if the connector health check cannot access the database
- Not all existing data in a stream is exported when stopping and then starting a stream
- Stream can miss entries upon initial ingestion (when a stream is created or restarted)
- Vocabulary key usage of deduplication project links to an unknown deduplication project
- Rule ordering is incorrect when a rule is invalidated from remapping or changing the data type of a vocabulary key
CluedIn.MicroService.Clean
CluedIn.MicroServices
Features
- Improved the ability to detect duplicates before inserting data to a data set
- Improved recoverability for connections to RabbitMQ
- Support for DuckDB and parquet files
- Improved recoverability for the internal MsSQL connection
Fixes
- Process list page can end up in an infinite loop when the data sets are submitting
- You are able to push data to an archived endpoint
- Retry loading in data set can fail
- When in bridge mode the total count is twice the expected value
- After switch out of bridge mode you cannot process more data
- Issue removing data set logs in certain circumstances
- Creating the same vocabulary keys just with different casing causes an error
CluedIn.UI.Gql
Fixes
- Perform multiple queries when expanding a node on the relations graph
- Nodes lose connections on the relations tab if you expand a node under certain circumstances
CluedIn.UI
Features
- Data set has an option to check for duplicate records when inserting new records
- A user that has a local password but is part of an organization that is using SSO can now change their local password
- Better support for theming on the relations tab
- Ability to reject a group on both tabs
- Changed
resultterm tomatchesfor the deduplication tab - Changed
merged entitiesterm tomergesfor the deduplication tab - Changed
Sign in to your teampage to referenceorganizationinstead ofteam - Confirmation modal when switching to auto submit on a dataset
- Removed unused links from the
Morebutton menu on an entity - Display a hint about existing unused vocabulary keys when using the vocabulary key picker
- Improved vocabulary key remapping information throughout the system
Fixes
- Dataset filters show blank values in the select list
- Deleted file that was currently uploading to data source continues to be uploaded
- Main shadow node becomes hidden when expanding records in the relations tab
- Disable ‘Generating Results’ progress bar on ‘Merged Entities’ tab on Deduplication project
- Merged entities tab is not updated after we have unmerged the entities from a deduplication project
- Cannot proceed with merge in deduplication if all entities have an empty value for a property
- Vocabulary keys being displayed with underscores on the data set preview tab
- Vocabulary key with a max length cannot be added as an edge property whilst mapping
- The data set data tab does not show all of the related entities under certain circumstances
- Missing entity icons causes the search page to display an error
Runtime-Environment
Features
- Added a field called
hashCheckto support the detection of duplicate items submitted to a data set - Added a field on the
dataSetstable to identify if a dedicated table should be used for logging - Added various tables and fields to support receipt ids in data source
Packages
For this release, kindly utilize the precise versions listed below for the following packages
Connectors
| Name | Version |
|---|---|
| CluedIn.Connector.AzureDataLake | 4.0.0 |
| CluedIn.Connector.AzureDedicatedSqlPool | 4.0.0 |
| CluedIn.Connector.AzureEventHub | 4.0.0 |
| CluedIn.Connector.AzureServiceBus | 4.0.0 |
| CluedIn.Connector.Http | 4.0.0 |
| CluedIn.Connector.SqlServer | 4.0.0 |
| CluedIn.PowerApps | 4.0.1 |
| CluedIn.Connector.Dataverse | 4.0.1 |
Enrichers
| Name | Version |
|---|---|
| CluedIn.ExternalSearch.Providers.DuckDuckGo.Provider | 4.0.0 |
| CluedIn.ExternalSearch.Providers.PermId.Provider | 4.0.0 |
| CluedIn.ExternalSearch.Providers.Web | 4.0.0 |
| CluedIn.Provider.ExternalSearch.Bregg | 4.0.0 |
| CluedIn.Provider.ExternalSearch.ClearBit | 4.0.0 |
| CluedIn.Provider.ExternalSearch.CompanyHouse | 4.0.0 |
| CluedIn.Provider.ExternalSearch.CVR | 4.0.0 |
| CluedIn.Provider.ExternalSearch.Gleif | 4.0.0 |
| CluedIn.Provider.ExternalSearch.GoogleMaps | 4.0.0 |
| CluedIn.Provider.ExternalSearch.KnowledgeGraph | 4.0.0 |
| CluedIn.Provider.ExternalSearch.Libpostal | 4.0.0 |
| CluedIn.Provider.ExternalSearch.OpenCorporates | 4.0.0 |
| CluedIn.Provider.ExternalSearch.Providers.VatLayer | 4.0.0 |
| CluedIn.Provider.MasterDataServices | 4.0.0 |
Crawlers
| Name | Version |
|---|---|
| CluedIn.Crawling.MasterDataServices | 4.0.0 |
| CluedIn.Purview | 4.2.0 |
Other
| Name | Version |
|---|---|
| CluedIn.Vocabularies.CommonDataModel | 4.0.1 |
| CluedIn.EventHub | 4.2.0 |
Tags
Clean
| Docker Image | Tags |
|---|---|
| cluedin/cluedin-micro-clean | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83761 |
Controller
| Docker Image | Tags |
|---|---|
| cluedin/controller | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83740 |
Docs
| Docker Image | Tags |
|---|---|
| cluedin/cluedin-micro-documentation | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83739 |
Gql
| Docker Image | Tags |
|---|---|
| cluedin/cluedin-ui-gql | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83738 |
Microservices
| Docker Image | Tags |
|---|---|
| cluedin/data-source | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83773 |
| cluedin/data-source-processing | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83773 |
| cluedin/data-source | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83773 |
| cluedin/data-source-processing | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83773 |
| cluedin/data-source-submitter | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83773 |
| cluedin/data-source | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83773 |
Runtime
| Docker Image | Tags |
|---|---|
| cluedin/neo4j | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83741 |
| cluedin/openrefine | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83741 |
Server
| Docker Image | Tags |
|---|---|
| cluedin/cluedin-server | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83744, 4.2.0_83744-alpine, 4.2.0-alpine, 4.2-alpine |
| cluedin/cluedin-server | 2024.04.00, 2024.04, 4.2.0_83744-ubuntu, 4.2.0-ubuntu, 4.2-ubuntu |
| cluedin/nuget-installer | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83744, 4.2.0_83744-alpine, 4.2.0-alpine, 4.2-alpine |
| cluedin/nuget-installer | 2024.04.00, 2024.04, 4.2.0_83744-ubuntu, 4.2.0-ubuntu, 4.2-ubuntu |
Ui
| Docker Image | Tags |
|---|---|
| cluedin/ui | 2024.04.00, 2024.04, 4.2, 4.2.0, 4.2.0_83737 |